Why LSP?
LSP (language server protocol) is fairly popular today. There’s a standard explanation of why that is the case. You probably have seen this picture before:

I believe that this standard explanation of LSP popularity is wrong. In this post, I suggest an alternative picture.
Standard Explanation
The explanation goes like this:
There are M editors and N languages.
If you want to support a particular language in a particular editor, you need to write a dedicated plugin for that.
That means M * N work, as the picture on the left vividly demonstrates.
What LSP does is cutting that to M + N, by providing a common thin waist, as show on the right picture.
Why is the explanation wrong?
The problem with the explanation is that also best to illustrate pictorially. In short, the picture above is not drawn to scale. Here’s a better illustration of how, for example, rust-analyzer + VS Code combo works together:
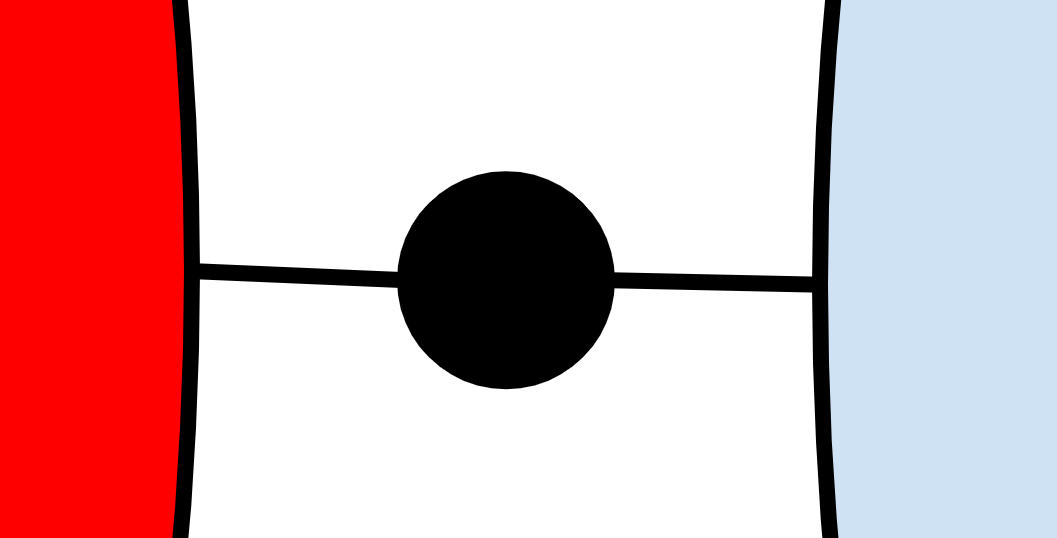
The (big) ball on the left is rust-analyzer — a language server. The similarly sized ball on the right is VS Code — an editor. And the small ball in the center is the code to glue them together, including LSP implementations.
That code is relatively and absolutely tiny. The codebases behind either the language server or the editor are enormous.
If the standard theory were correct, then, before LSP, we would have lived in a world where some languages has superb IDE support in some editors. For example, IntelliJ would have been great at Java, Emacs at C++, Vim at C#, etc. My recollection of that time is quite different. To get a decent IDE support, you either used a language supported by JetBrains (IntelliJ or ReSharper) or.
There was just a single editor providing meaningful semantic IDE support.
Alternative Theory
I would say that the reason for such poor IDE support in the days of yore is different.
Rather than M * N being too big, it was too small, because N was zero and M just slightly more than that.
I’d start with N — the number of language servers, this is the side I am relatively familiar with.
Before LSP, there simply weren’t a lot of working language-server shaped things.
The main reason for that is that building a language server is hard.
The essential complexity for a server is pretty high. It is known that compilers are complicated, and a language server is a compiler and then some.
First, like a compiler, a language server needs to fully understand the language, it needs to be able to distinguish between valid and invalid programs. However, while for invalid programs a batch compiler is allowed to emit an error message and exit promptly, a language server must analyze any invalid program as best as it can. Working with incomplete and invalid programs is the first complication of a language server in comparison to a compiler.
Second, while a batch compiler is a pure function which transforms source text into machine code, a language server has to work with a code base which is constantly being modified by the user. It is a compiler with a time dimension, and evolution of state over time is one of the hardest problems in programming.
Third, a batch compiler is optimized for maximum throughput, while a language server aims to minimize latency (while not completely forgoing throughput). Adding a latency requirement doesn’t mean that you need to optimize harder. Rather, it means that you generally need to turn the architecture on its head to have an acceptable latency at all.
And this brings us to a related cluster of accidental complexity surrounding language servers. It is well understood how to write a batch compiler. It’s common knowledge. While not everyone have read the dragon book (I didn’t meaningfully get past the parsing chapters), everyone knows that that book contains all the answers. So most existing compilers end up looking like a typical compiler. And, when compiler authors start thinking about IDE support, the first thought is “well, IDE is kinda a compiler, and we have a compiler, so problem solved, right?”. This is quite wrong — internally an IDE is very different from a compiler but, until very recently, this wasn’t common knowledge.
Language servers are a counter example to the “never rewrite” rule. Majority of well regarded language servers are rewrites or alternative implementations of batch compilers.
Both IntelliJ and Eclipse wrote their own compilers rather than re-using javac inside an IDE. To provide an adequate IDE support for C#, Microsoft rewrote their batch compiler written in C++ into an interactive self-hosted one (project Roslyn). Dart, despite being a from-scratch, relatively modern language, ended up with three implementations (host AOT compiler, host IDE compiler (dart-analyzer), on-device JIT compiler). Rust tried both — incremental evolution of rustc (RLS) and from-scratch implementation (rust-analyzer), and rust-analyzer decisively won.
The two exceptions I know are C++ and OCaml. Curiously, both require forward declarations and header files, and I don’t think this is a coincidence. See the Three Architectures for a Responsive IDE post for details.
To sum up, on the language server’s side things were in a bad equilibrium. It was totally possible to implement language servers, but that required a bit of an iconoclastic approach, and it’s hard to be a pioneering iconoclast.
I am less certain what was happening on the editor’s side. Still, I do want to claim that we had no editors capable of being an IDE.
IDE experience consists of a host of semantic features. The most notable example is, of course completion. If one wants to implement custom completion for VS Code, one needs to implement CompletionItemProvider interface:
interface CompletionItemProvider {
provideCompletionItems(
document: TextDocument,
position: Position,
): CompletionItem[]
}This means that, in VS Code, code completion (as well as dozens of other IDE related features) is an editor’s first-class concept, with uniform user UI and developer API.
Contrast this with Emacs and Vim. They just don’t have proper completion as an editor’s extension point. Rather, they expose low-level cursor and screen manipulation API, and then people implement competing completion frameworks on top of that!
And that’s just code completion! What about parameter info, inlay hints, breadcrumbs, extend selection, assists, symbol search, find usages (I’ll stop here :) )?
To sum the above succinctly, the problem with decent IDE support was not of N * M, but rather of an inadequate equilibrium of a two-sided market.
Language vendors were reluctant to create language servers, because it was hard, the demand was low (= no competition from other languages), and, even if one creates a language server, one would find a dozen editors absolutely unprepared to serve as a host for a smart server.
On the editor’s side, there was little incentive for adding high-level APIs needed for IDEs, because there were no potential providers for those APIs.
Why LSP is great
And that’s why I think LSP is great!
I don’t think it was a big technical innovation (it’s obvious that you want to separate a language-agnostic editor and a language-specific server). I think it’s a rather bad (aka, “good enough”) technical implementation (stay tuned for “Why LSP sucks?” post I guess? (update)). But it moved us from a world where not having a language IDE was normal and no one was even thinking about language servers, to a world where a language without working completion and goto definition looks unprofessional.
Notably, the two-sided market problem was solved by Microsoft, who were a vendor of both languages (C# and TypeScript) and editors (VS Code and Visual Studio), and who were generally losing in the IDE space to a competitor (JetBrains). While I may rant about particular technical details of LSP, I absolutely admire their strategic vision in this particular area. They:
- built an editor on web technologies.
- identified webdev as a big niche where JetBrains struggles (supporting JS in an IDE is next to impossible).
- built a language (!!!!) to make it feasible to provide IDE support for webdev.
-
built an IDE platform with a very forward-looking architecture (stay tuned for a post where I explain why
vscode.d.tsis a marvel of technical excellence). - launched LSP to increase the value of their platform in other domains for free (moving the whole world to a significantly better IDE equilibrium as a collateral benefit).
- and now, with code spaces, are posed to become the dominant player in the “remote first development”, should we indeed stop editing, building, and running code on our local machines.
Though, to be fair, I still hope that, in the end, the winner would be JetBrains with their idea of Kotlin as a universal language for any platform :-) While Microsoft takes full advantage of worse-is-better technologies which are dominant today (TypeScript and Electron), JetBrains tries to fix things from the bottom up (Kotlin and Compose).
More on M * N
Now I am just going to hammer it in that it’s really not M * N :)
First, M * N argument ignores the fact that this is an embarrassingly parallel problem.
Neither language designers need to write plugins for all editors, nor editors need to add special support for all languages.
Rather, a language should implement a server which speaks some protocol, an editor needs to implement language agnostic APIs for providing completions and such, and, if both the language and the editor are not esoteric, someone who is interested in both would just write a bit of glue code to bind the two together!
rust-analyzer’s VS Code plugin is 3.2k lines of code, neovim plugin is 2.3k and Emacs plugin is 1.2k.
All three are developed independently by different people.
That’s the magic of decentralized open source development at its finest!
If the plugins were to support custom protocol instead of LSP (provided that the editor supports high-level IDE API inside), I’d expect to add maybe 2k lines for that, which is still well within hobbyist working part-time budget.
Second, for M * N optimization you’d expect the protocol implementation to be generated from some machine readable implementation.
But until the latest release, the source of truth for LSP spec was an informal markdown document.
Every language and client was coming up with their own way to extract protocol out of it, many (including rust-analyzer) were just syncing the changes manually, with quite a bit of duplication.
Third, if M * N is a problem, you’d expect to see only one LSP implementation for each editor.
In reality, there are two competing Emacs implementations (lsp-mode and eglot) and, I kid you not, at the time of writing rust-analyzer’s manual contains instruction for integration with 6 (six) different LSP clients for vim.
To echo the first point, this is open source!
The total amount of work is almost irrelevant, the thing that matters is the amount of coordination to get things done.
Fourth, Microsoft itself doesn’t try to take advantage of M + N.
There’s no universal LSP implementation in VS Code.
Instead, each language is required to have a dedicated plugin with physically independent implementations of LSP.
Action Items
- Everyone
-
Please demand better IDE support! I think today we crossed the threshold of general availability of baseline IDE support, but there’s so much we can do beyond the basics. In the ideal world, it should be possible to inspect every little semantic details about expression at the cursor, using the same simple API one can use today to inspect contents of editor’s buffer.
- Text Editor Authors
-
Pay attention to the architecture of VS Code. While electron delivers questionable user experience, the internal architecture has a lot of wisdom in it. Do orient editor’s API around presentation-agnostic high-level features. Basic IDE functionality should be a first-class extension point, it shouldn’t be re-invented by every plugin’s author. In particular, add assist/code action/💡 as a first-class UX concept already. It’s the single most important UX innovation of IDEs, which is very old at this point. Its outright ridiculous that this isn’t a standard interface across all editors.
But don’t make LSP itself a first class concept. Surprising as it might seem, VS Code knows nothing about LSP. It just provides a bunch of extension points without caring the least how they are implemented. LSP implementation then is just a library, which is used by language-specific plugins. E.g., Rust and C++ extensions for VS Code do not share the same LSP implementation at runtime, there are two copies of LSP library in memory!
Also, try to harness the power of open-source. Don’t enforce centralization of all LSP implementations! Make it possible for separate groups of people to independently work on perfect Go support and perfect Rust support for your editor. VS Code is one possible model, with a marketplace and distributed, independent plugins. But it probably should be possible to organize the work as a single shared repo/source tree, as long as languages can have independent maintainers sets
- Language Server Authors
-
You are doing a great job! The quality of IDE support is improving rapidly for all the languages, though I feel this is only a beginning of a long road. One thing to keep in mind is that LSP is an interface to a semantic info about the language, but it isn’t the interface. A better thing might come along. Even today, limitations of LSP prevent from shipping useful features. So, try to treat LSP as a serialization format, not as an internal data model. And try to write more about how to implement language servers — I feel like there’s still not enough knowledge about this out there.
That’s it!
P.S. If by any chance you are benefiting from using rust-analyzer, consider sponsoring Ferrous Systems Open Source Collective for rust-analyzer to support its development!