How to Test
Alternative titles:
Unit Tests are a Scam
Test Features, Not Code
Data Driven Integrated Tests
This post describes my current approach to testing. When I started programming professionally, I knew how to write good code, but good tests remained a mystery for a long time. This is not due to the lack of advice — on the contrary, there’s abundance of information & terminology about testing. This celestial emporium of benevolent knowledge includes TDD, BDD, unit tests, integrated tests, integration tests, end-to-end tests, functional tests, non-functional tests, blackbox tests, glassbox tests, …
Knowing all this didn’t help me to create better software. What did help was trying out different testing approaches myself, and looking at how other people write tests. Keep in mind that my background is mostly in writing compiler front-ends for IDEs. This is a rather niche area, which is especially amendable to testing. Compilers are pure self-contained functions. I don’t know how to best test modern HTTP applications built around inter-process communication.
Without further ado, let’s see what I have learned!
Further ado(2024-05-21): while writing this post, I was missing a key piece of terminology for crisply describing various kinds of tests. If you like this post, you might want to read Unit and Integration Tests . That post supplies better vocabulary for talking about phenomena described in the present article.
Test Driven Design Ossification
This is something I inflicted upon myself early in my career, and something I routinely observe. You want to refactor some code, say add a new function parameter. Turns out, there are a dozen of tests calling this function, so now a simple refactor also involves fixing all the tests.
There is a simple, mechanical fix to this problem: introduce the check function which encapsulates API under test.
It’s easier to explain using a toy example.
Let’s look at testing something simple, like a binary search, just to illustrate the technique.
We start with direct testing:
/// Given a *sorted* `haystack`, returns `true`
/// if it contains the `needle`.
fn binary_search(haystack: &[T], needle: &T) -> bool {
...
}
fn binary_search_empty() {
let res = binary_search(&[], &0);
assert_eq!(res, false);
}
fn binary_search_singleton() {
let res = binary_search(&[92], &0);
assert_eq!(res, false);
let res = binary_search(&[92], &92);
assert_eq!(res, true);
let res = binary_search(&[92], &100);
assert_eq!(res, false);
}
// And a dozen more of other similar tests...Some time passes, and we realize that -> bool is not the best signature for binary search.
It’s better if it returned an insertion point (an index where element should be inserted to maintain sortedness).
That is, we want to change the signature to
fn binary_search(haystack: &[T], needle: &T) -> Result<usize, usize>;Now we have to change every test, because the tests are tightly coupled to the specific API.
My solution to this problem is making the tests data driven.
Instead of every test interacting with the API directly, I like to define a single check function which calls the API.
This function takes a pair of input and expected result.
For binary search example, it will look like this:
fn check(
input_haystack: &[i32],
input_needle: i32,
expected_result: bool,
) {
let actual_result =
binary_search(input_haystack, &input_needle);
assert_eq!(expected_result, actual_result);
}
fn binary_search_empty() {
check(&[], 0, false);
}
fn binary_search_singleton() {
check(&[92], 0, false);
check(&[92], 92, true);
check(&[92], 100, false);
}Now, when the API of the binary_search function changes, we only need to adjust the single place — check function:
fn check(
input_haystack: &[i32],
input_needle: i32,
expected_result: bool,
) {
let actual_result =
binary_search(input_haystack, &input_needle).is_ok();
assert_eq!(expected_result, actual_result);
}To be clear, after you’ve done the refactor, you’ll need to adjust the tests to check the index as well, but this can be done separately. Existing test suite does not impede changes.
Keep in mind that the binary search example is artificially simple. The main danger here is that this is a boiling frog type of situation. While the project is small and the tests are few, you don’t notice that refactors are ever so slightly longer than necessary. Then, several tens of thousands lines of code later, you realize that to make a simple change you need to fix a hundred tests.
Test Friction
Almost no one likes to write tests. I’ve noticed many times how, upon fixing a trivial bug, I am prone to skipping the testing work. Specifically, if writing a test is more effort than the fix itself, testing tends to go out of the window. Hence,
Coming back to the binary search example, note how check function reduces the amount of typing to add a new test.
For tests, this is a significant saving, not because typing is hard, but because it lowers the cognitive barrier to actually do the work.
Test Features, Not Code
The over-simplified binary search example can be stretched further. What if you replace the sorted array with a hash map inside your application? Or what if the calling code no longer needs to search at all, and wants to process all of the elements instead?
Good code is easy to delete. Tests represent an investment into existing code, and make it costlier to delete (or change).
The solution is to write tests for features in such a way that they are independent of the code. I like to use the neural network test for this:
- Neural Network Test
-
Can you re-use the test suite if your entire software is replaced with an opaque neural network?
To give a real-life example this time, suppose that you are writing that part of code-completion engine which sorts potential completions according to relevance. (something I should probably be doing right now, instead of writing this article :-) )
Internally, you have a bunch of functions that compute relevance facts, like:
-
Is there direct type match (
.foohas the desired type)? -
Is there an indirect type match (
.foo.barhas the right type)? - How frequently is this completion used in the current module?
Then, there’s the final ranking function that takes these facts and comes up with an overall rank.
The classical unit-test approach here would be to write a bunch of isolated tests for each of the relevance functions, and a separate bunch of tests which feeds the ranking function a list of relevance facts and checks the final score.
This approach obviously fails the neural network test.
An alternative approach is to write a test to check that at a given position a specific ordered list of entries is returned. That suite could work as a cross-validation for an ML-based implementation.
In practice, it’s unlikely (but not impossible), that we use actual ML here. But it’s highly probably that the naive independent weights model isn’t the end of the story. At some point there will be special cases which would necessitate change of the interface.
Note that this advice goes directly against one common understanding of unit-testing. I am fairly confident that it results in better software over the long run.
Make Tests Fast
There’s one talk about software engineering, which stands out for me, and which is my favorite. It is Boundaries by Gary Bernhardt. There’s a point there though, which I strongly disagree with:
- Integration Tests are Superlinear?
-
When you use integration tests, any new feature is accompanied by a bit of new code and a new test. However, new code slows down all other tests, so the the overall test suite becomes slow, as the total time grows super-linearly.
I don’t think more code under test translates to slower test suite. Merge sort spends more lines of code than bubble sort, but it is way faster.
In the abstract, yes, more code generally means more execution time, but I doubt this is the defining factor in tests execution time. What actually happens is usually:
- Input/Output — reading just a bit from a disk, network or another process slows down the tests significantly.
- Outliers — very often, testing time is dominated by only a couple of slow tests.
- Overly large input — throwing enough data at any software makes it slow.
The problem with integrated tests is not code volume per se, but the fact that they typically mean doing a lot of IO. But this doesn’t need to be the case
Nonetheless, some tests are going to be slow. It pays off to introduce the concept of slow tests early on, arrange the skipping of such tests by default and only exercise them on CI. You don’t need to be fancy, just checking an environment variable at the start of the test is perfectly fine:
fn completion_works_with_real_standard_library() {
if std::env::var("RUN_SLOW_TESTS").is_err() {
return;
}
...
}Definitely do not use conditional compilation to hide slow tests — it’s an obvious solution which makes your life harder (similar observation from the Go ecosystem).
To deal with outliers, print each test’s execution time by default. Having the numbers fly by gives you immediate feedback and incentive to improve.
Data Driven Testing
All these together lead to a particular style of architecture and tests, which I call data driven testing. The bulk of the software is a pure function, where the state is passed in explicitly. Removing IO from the picture necessitates that the interface of software is specified in terms of data. Value in, value out.
One property of data is that it can be serialized and deserialized.
That means that the check style tests can easily accept arbitrary complex input, which is specified in a structured format (JSON), ad-hoc plain text format, or via embedded DSL (builder-style interface for data objects).
Similarly, The “expected” argument of check is data.
It is a result which is more-or-less directly displayed to the user.
A convincing example of a data driven test would be a “Goto Definition” tests from rust-analyzer (source):
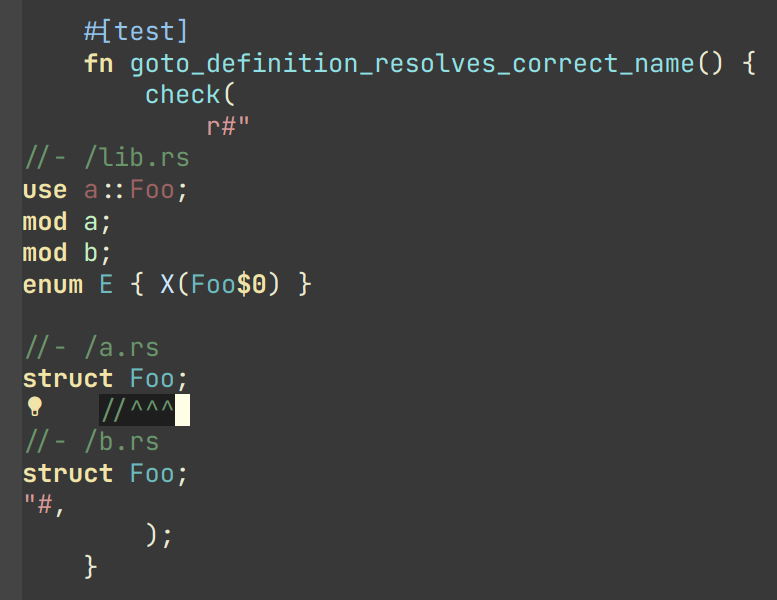
In this case, the check function has only a single argument — a string which specifies both the input and the expected result.
The input is a rust project with three files (//- /file.rs syntax shows the boundary between the files).
The current cursor position is also a part of the input and is specified with the $0 syntax.
The result is the //^^^ comment which marks the target of the “Goto Definition” call.
The check function creates an in-memory Rust project, invokes “Goto Definition” at the position signified by $0, and checks that the result is the position marked with ^^^.
Note that this is decidedly not a unit test. Nothing is stubbed or mocked. This test invokes the whole compilation pipeline: virtual file system, parser, macro expander, name resolution. It runs on top of our incremental computation engine. It touches a significant fraction of the IDE APIs. Yet, it takes 4ms in debug mode (and 500µs in release mode). And note that it absolutely does not depend on any internal API — if we replace our dumb compiler with sufficiently smart neural net, nothing needs to be adjusted in the tests.
There’s one question though: why on earth am I using a png image to display a bit of code?
Only to show that the raw string literal (r#""#) which contains Rust code is highlighted as such.
This is possible because we re-use the same input format (with //-, $0 and couple of other markup elements) for almost every test in rust-analyzer.
As such, we can invest effort into building cool things on top of this format, which subsequently benefit all our tests.
Expect Tests
Previous example had a complex data input, but a relatively simple data output — a position in the file.
Often, the output is messy and has a complicated structure as well (a symptom of rho problem).
Worse, sometimes the output is a part that is changed frequently.
This often necessitates updating a lot of tests.
Going back to the binary search example, the change from -> bool to -> Result<usize, usize> was an example of this effect.
There is a technique to make such simultaneous changes to all gold outputs easy — testing with expectations. You specify the expected result as a bit of data inline with the test. There’s a special mode of running the test suite for updating this data. Instead of failing the test, a mismatch between expected and actual causes the gold value to be updated in-place. That is, the test framework edits the code of the test itself.
Here’s an example of this workflow in rust-analyzer, used for testing code completion:
Often, just Debug representation of the type works well for expect tests, but you can do something more fun.
See this post from Jane Street for a great example:
Using ASCII waveforms to test hardware designs.
There are several libraries for this in Rust: insta, k9, expect-test.
Fluent Assertions
An extremely popular genre for a testing library is a collection of fluent assertions:
// Built-in assertion:
assert!(x > y);
// Fluent assertion:
assert_that(x).is_greater_than(y);The benefit of this style are better error messages.
Instead of just “false is not true”, the testing framework can print values for x and y.
I don’t find this useful.
Using the check style testing, there are very few assertions actually written in code.
Usually, I start with plain asserts without messages.
The first time I debug an actual test failure for a particular function, I spend some time to write a detailed assertion message.
To me, fluent assertions are not an attractive point on the curve that includes plain asserts and hand-written, context aware explanations of failures.
A notable exception here is pytest approach — this testing framework overrides the standard assert to provide a rich diff without ceremony.
Peeking Inside
One apparent limitation of the style of integrated testing I am describing is checking for properties which are not part of the output. For example, if some kind of caching is involved, you might want to check that the cache is actually being hit, and is not just sitting there. But, by definition, cache is not something that an outside client can observe.
The solution to this problem is to make this extra data a part of the system’s output by adding extra observability points. A good example here is Cargo’s test suite. It is set-up in an integrated, data-driven fashion. Each tests starts with a succinct DSL for setting up a tree of files on disk. Then, a full cargo command is invoked. Finally, the test looks at the command’s output and the resulting state of the file system, and asserts the relevant facts.
Tests for caching additionally enable verbose internal logging. In this mode, Cargo prints information about cache hits and misses. These messages are then used in assertions.
A close idea is coverage marks. Some times, you want to check that something does not happen. Tests for this tend to be fragile — often the thing does not happen, but for the wrong reason. You can add a side channel which explains the reasoning behind particular behavior, and additionally assert this as well.
Externalized Tests
In the ultimate stage of data driven tests the definitions of test cases are moved out of test functions and into external files. That is, you don’t do this:
fn test_foo() {
check("foo", "oof")
}
fn test_bar() {
check("bar", "rab")
}Rather, there is a single test that looks like this:
fn test_all() {
for file in read_dir("./test_data/in") {
let input = read_to_string(
&format!("./test_data/in/{}", file),
);
let output = read_to_string(
&format!("./test_data/out/{}", file),
);
check(input, output)
}
}I have a love-hate relationship with this approach. It has at least two attractive properties. First, it forces data driven approach without any cheating. Second, it makes the test suite more re-usable. An alternative implementation in a different programming language can use the same tests.
But there’s a drawback as well — without literal #[test] attributes, integration with tooling suffers.
For example, you don’t automatically get “X out of Y tests passed” at the end of test run.
You can’t conveniently debug just a single test, there isn’t a helpful “Run” icon/shortcut you can use in an IDE.
When I do externalized test cases, I like to leave a trivial smoke test behind:
fn smoke() {
check("", "");
}If I need to debug a failing external test, I first paste the input into this smoke test, and then get my IDE tooling back.
Beyond Example Based Testing
Reading from a file is not the most fun way to come up with a data input for a check function.
Here are a few other popular ones:
- Property Based Testing
-
Generate the input at random and verify that the output makes sense. For a binary search, check that the
needleindeed lies between the two elements at the insertion point. - Full Coverage
-
Better still, instead of generating some random inputs, just check that the answer is correct for all inputs. This is how you should be testing binary search — generate every sorted list of length at most
7with numbers in the0..=6range. Then, for each list and for each number, check that the binary search gives the same result as a naive linear search. - Coverage Guided Fuzzing
-
Just throw random bytes at the check function. Random bytes probably don’t make much sense, but it’s good to verify that the program returns an error instead of summoning nasal demons. Instead of piling bytes completely at random, observe which branches are taken, and try to invent byte sequences which cover more branches. Note that this test is polymorphic in the system under test.
- Structured Fuzzing / Coverage Guided Property Testing
-
Use random bytes as a seed to generate “syntactically valid” inputs, then see you software crash and burn when the most hideous edge cases are uncovered. If you use Rust, check out wasm-smith and arbitrary crates.
The External World
What if isolating IO is not possible, and the application is fundamentally build around interacting with external systems? In this case, my advice is to just accept that the tests are going to be slow, and might need extra effort to avoid flakiness.
Cargo is the perfect case study here. Its raison d’être is orchestrating a herd of external processes. Let’s look at the basic test:
fn cargo_compile_simple() {
let p = project()
.file("Cargo.toml", &basic_bin_manifest("foo"))
.file("src/foo.rs", &main_file(r#""i am foo""#, &[]))
.build();
p.cargo("build").run();
assert!(p.bin("foo").is_file());
p.process(&p.bin("foo")).with_stdout("i am foo\n").run();
}The project() part is a builder, which describes the state of the a system.
First, .build() writes the specified files to a disk in a temporary directory.
Then, p.cargo("build").run() executes the real cargo build command.
Finally, a bunch of assertions are made about the end state of the file system.
Neural network test: this is completely independent of internal Cargo APIs, by virtue of interacting with a cargo process via IPC.
To give an order-of-magnitude feeling for the cost of IO, Cargo’s test suite takes around seven minutes (-j 1), while rust-analyzer finishes in less than half a minute.
An interesting case is the middle ground, when the IO-ing part is just big and important enough to be annoying. That is the case for rust-analyzer — although almost all code is pure, there’s a part which interacts with a specific editor. What makes this especially finicky is that, in the case of Cargo, it’s Cargo who calls external processes. With rust-analyzer, it’s something which we don’t control, the editor, which schedules the IO. This often results in hard-to-imagine bugs which are caused by particularly weird environments.
I don’t have good answers here, but here are the tricks I use:
- Accept that something will break during integration. Even if you always create perfect code and never make bugs, your upstream integration point will be buggy sometimes.
-
Make integration bugs less costly:
- use release trains,
- make patch release process non-exceptional and easy,
- have a checklist for manual QA before the release.
- Separate the tricky to test bits into a separate project. This allows you to write slow and not 100% reliable tests for integration parts, while keeping the core test suite fast and dependable.
The Concurrent World
Consider the following API:
fn do_stuff_in_background(p: Param) {
std::thread::spawn(move || {
// Stuff
})
}This API is fundamentally untestable.
Can you see why?
It spawns a concurrent computation, but it doesn’t allow waiting for this computation to be finished.
So, any test that calls do_stuff_in_background can’t check that the “Stuff” is done.
Worse, even tests which do not call this function might start to fail — they now can get interference from other tests.
The concurrent computation can outlive the test that originally spawned it.
This problem plagues almost every concurrent application I see. A common symptom is adding timeouts and sleeps to test, to increase the probability of stuff getting done. Such timeouts are another common cause of slow test suites.
What makes this problem truly insidious is that there’s no work-around. Broken once, causality link is not reforgable by a layer above.
The solution is simple: don’t do this.
Layers
Another common problem I see in complex projects is a beautifully layered architecture, which is “inverted” in tests.
Let’s say you have something fabulous, like L1 <- L2 <- L3 <- L4.
To test L1, the path of least resistance is often to write tests which exercise L4.
You might even think that this is the setup I am advocating for.
Not exactly.
The problem with L1 <- L2 <- L3 <- L4 <- Tests is that working on L1 becomes slower, especially in compiled languages.
If you make a change to L1, then, before you get to the tests, you need to recompile the whole chain of reverse dependencies.
My “favorite” example here is rustc — when I worked on the lexer (T1), I spent a lot of time waiting for the rest of the compiler to be rebuild to check my small change.
The right setup here is to write integrated tests for each layer:
L1 <- Tests
L1 <- L2 <- Tests
L1 <- L2 <- L3 <- Tests
L1 <- L2 <- L3 <- L4 <- TestsNote that testing L4 involves testing L1, L2 an L3.
This is not a problem.
Due to layering, only L4 needs to be recompiled.
Other layers don’t affect run time meaningfully.
Remember — it’s IO (and sleep-based synchronization) that kills performance, not just code volume.
Test Everything
In a nutshell, a #[test] is just a bit of code which is plugged into the build system to be executed automatically.
Use this to your advantage, simplify the automation by moving as much as possible into tests.
Here’s some things in rust-analyzer which are just tests:
- Code formatting (most common one — you don’t need an extra pile of YAML in CI, you can shell out to the formatter from the test).
- Checking that the history does not contain merge commits and teaching new contributors git survival skills.
- Collecting the manual from specially-formatted doc comments across the code base.
- Checking that the code base is, in fact, reasonably well-documented.
- Ensuring that the licenses of dependencies are compatible.
- Ensuring that high-level operations are linear in the size of the input. Syntax-highlight a synthetic file of 1, 2, 4, 8, 16 kilobytes, run linear regression, check that result looks like a line rather than a parabola.
Use Bors
This essay already mentioned a couple of cognitive tricks for better testing: reducing the fixed costs for adding new tests, and plotting/printing test times. The best trick in a similar vein is the “not rocket science” rule of software engineering.
The idea is to have a robot which checks that the merge commit passes all the tests, before advancing the state of the main branch.
Besides the evergreen master, such bot adds pressure to keep the test suite fast and non-flaky. This is another boiling frog, something you need to constantly keep an eye on. If you have any a single flaky test, it’s very easy to miss when the second one is added.
Recap
This was a long essay. Let’s look back at some of the key points:
- There is a lot of information about testing, but it is not always helpful. At least, it was not helpful for me.
- The core characteristic of the test suite is how easy it makes changing the software under test.
- To that end, a good strategy is to focus on testing the features of the application, rather than on testing the code used to implement those features.
- A good test suite passes the neural network test — it is still useful if the entire application is replaced by an ML model which just comes up with the right answer.
- Corollary: good tests are not helpful for design in the small — a good test won’t tell you the best signatures for functions.
- Testing time is something worth optimizing for. Tests are sensitive to IO and IPC. Tests are relatively insensitive to the amount of code under tests.
- There are useful techniques which are underused — expectation tests, coverage marks, externalized tests.
- There are not so useful techniques which are over-represented in the discourse: fluent assertions, mocks, BDD.
- The key for unlocking many of the above techniques is thinking in terms of data, rather than interfaces or objects.
- Corollary: good tests are helpful for design in the large. They help to crystalize the data model your application is built around.
Links
- https://www.destroyallsoftware.com/talks/boundaries
- https://www.tedinski.com/2019/03/19/testing-at-the-boundaries.html
- https://programmingisterrible.com/post/139222674273/how-to-write-disposable-code-in-large-systems
- https://sans-io.readthedocs.io
- https://peter.bourgon.org/blog/2021/04/02/dont-use-build-tags-for-integration-tests.html
- https://buttondown.email/hillelwayne/archive/cross-branch-testing/
- https://blog.janestreet.com/testing-with-expectations/
- https://blog.janestreet.com/using-ascii-waveforms-to-test-hardware-designs/
- https://ferrous-systems.com/blog/coverage-marks/
- https://vorpus.org/blog/notes-on-structured-concurrency-or-go-statement-considered-harmful/
- https://graydon2.dreamwidth.org/1597.html
- https://bors.tech
- https://fsharpforfunandprofit.com/posts/property-based-testing/
- https://fsharpforfunandprofit.com/posts/property-based-testing-1/
- https://fsharpforfunandprofit.com/posts/property-based-testing-2/
- https://www.sqlite.org/testing.html
Somewhat amusingly, after writing this article I’ve learned about an excellent post by Tim Bray which argues for the opposite point:
https://www.tbray.org/ongoing/When/202x/2021/05/15/Testing-in-2021